|
特斯拉超级计算机又有更新放出! 车东西8月25号消息,据外媒electrek报道,近日特斯拉发布了两个有关Dojo AI超级计算机的深入演示,主要是关于特斯拉Dojo AI系统微架构和Dojo超级计算机的。 据了解,Dojo是特斯拉从头开始构建、自研的超级计算机平台,主要用于AI机器学习,更具体地说是,通过特斯拉车队的视频数据进行训练。 之前特斯拉已经有了一台基于英伟达GPU的大型超级计算机,是世界上最强大的超级计算机之一。在去年特斯拉的AI Day上,特斯拉推出了Dojo超级计算机,目前这台最新的Dojo自研计算机使用的是特斯拉自研的D1芯片。 公开信息显示,今年的特斯拉的AI Day将于9月30日举办,但是本周特斯拉的Dojo团队在Hot Chip活动上做了两次演讲,以下是车东西对演讲PPT的简单整理。 一、Dojo AI系统全自研 自研专用指令集 特斯拉Dojo AI系统开发过程与车载系统类似,特斯拉自己雇佣了研究人员为其研发相关的芯片和系统。 目前,特斯拉正着眼于从头开始构建相关系统,不过,它不仅仅是在研发自己的人工智能芯片,它还在研发一台超级计算机。 从特斯拉公开的资料来看,特斯拉Dojo AI系统采用分布式架构,每个Dojo节点都有自己的CPU、内存和通信接口。而每个节点都有1.25MB的SRAM(静态随机存取存储器),然后每个节点都连接到一个2D网格。 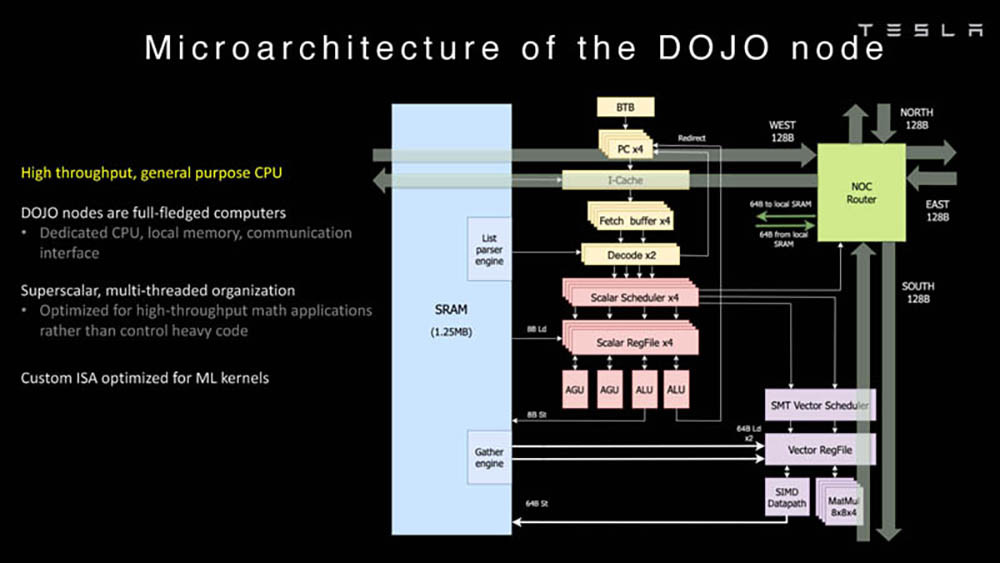 ▲节点 Dojo接口处理器位于2D网格的边缘,它的每个训练块有11GB的SRAM和160GB的共享DRAM(动态随机存取内存)。之后,这些元器件集成到了特斯拉D1芯片上。 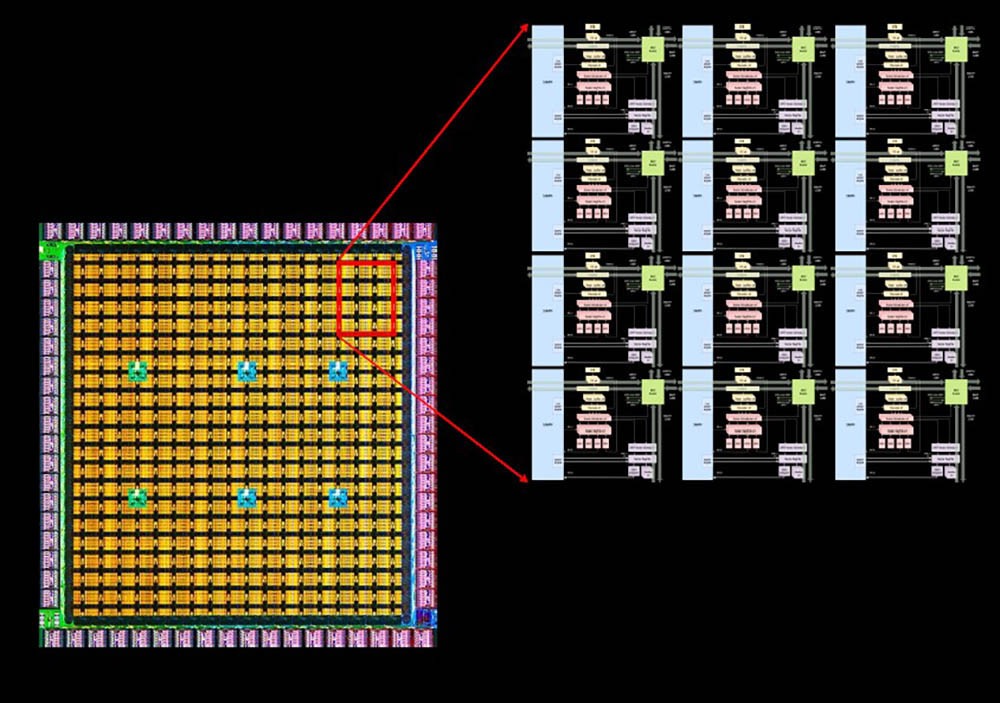 ▲D1芯片模型 特斯拉发言人介绍说,特斯拉D1芯片采用7nm工艺,由台积电制造,每个芯片有354个Dojo节点和440MB的 SRAM。 而在去年的特斯拉AI Day上,Dojo项目负责人Ganesh Venkataramanan也曾介绍过特斯拉D1芯片。当时他表示,特斯拉D1单芯片面积达645mm²,包含500亿个晶体管,BF16/CFP8峰值算力达362TFLOPS,FP32峰值算力达22.6TFLOPS,热设计功耗(TDP)不超过400W。 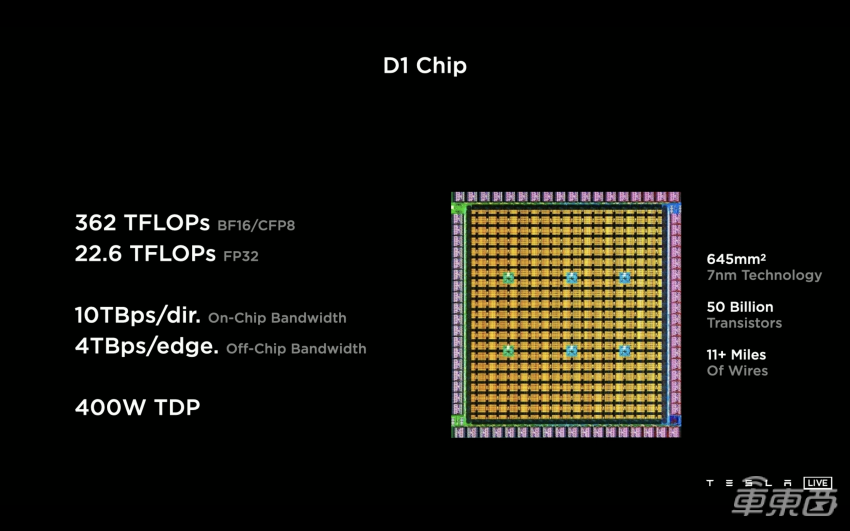 ▲去年特斯拉D1芯片的各项性能 该芯片具有GPU级别训练能力和CPU级别可控性,可实现50万个训练节点无缝连接。由此特斯拉提出由25个D1芯片组成的训练单元(Tile)。 一个训练单元的接口带宽每秒36TB,算力达9PFLOPS(每秒浮点运算次数),采用了集中供电和散热设计,散热能力15kW。 拥有120个训练单元、3000颗D1芯片、超过100万个训练节点的特斯拉机柜模型ExaPOD,其BF16/CFP8算力高达1.1EFLOPS(1 EFLOPS等于每秒一百京(=10^18)次的浮点运算)。 其分布式系统是分区块的,Dojo处理单元DPU(Dojo Processing Unit)是一个可根据应用需求调整大小的虚拟设备,包含多个D1芯片和接口处理器。特斯拉编译器引擎可自动将执行指令映射到DPU上,无需人工操作。可以说,特斯拉打造了一整套软件堆栈。 值得一提的是,特斯拉还为Dojo超算建立了专用的Dojo指令集,并未直接使用Intel、Arm、NVIDIA或AMD CPU/GPU的指令集。目前,Dojo支持像FP32、FP16和BFP16这样行业通用的数据格式。 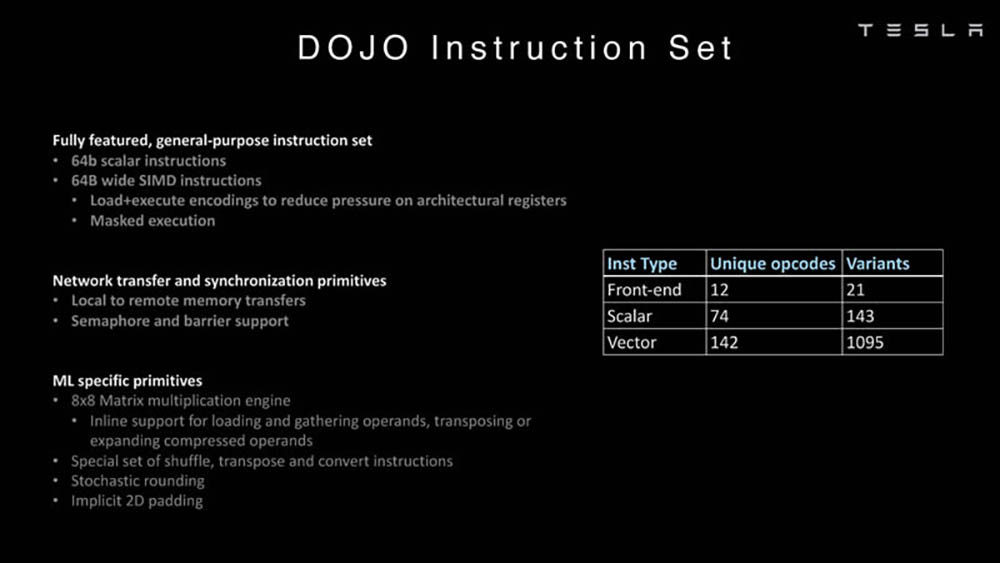 ▲指令集 依托于算力如此强大的超级计算机和AI芯片,特斯拉可以收集车辆的行驶数据并回传至特斯拉自动驾驶研发部门,然后特斯拉根据相似的场景进行分类,再进行分类机器学习训练,这样让特斯拉的AI算法更强大,也更加“聪明”。 二、超算可处理大量视频 匹配已有模型 因为特斯拉需要大量计算来实现自动驾驶汽车和卡车正常运行,这包括处理大量视频数据。所以对特斯拉超算来说,这比仅查看文本或静态图像更具挑战性。  ▲基于视频的训练 以下是特斯拉处理视频的两个内部模型,而这两者都可以由单个主机处理。不过其他计算机可能会数据负载受限的,例如无法由单个主机处理的第三个模型。 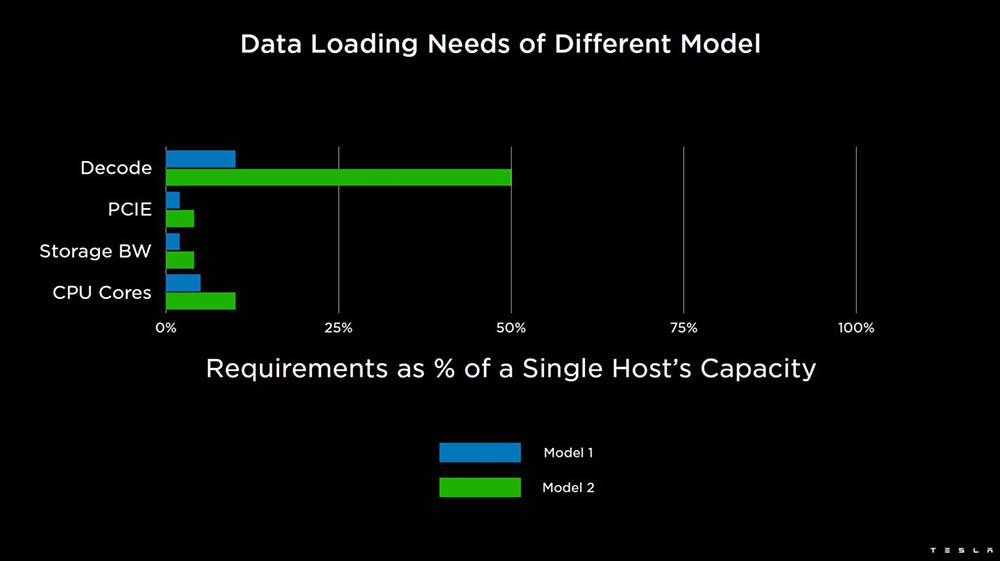 ▲特斯拉的两个内部模型 而特斯拉超算可以通过分解主机层,为数据加载/视频处理等添加更多处理,让每个模型都能得到及时的处理。另外,由于模型使用不同数量的资源,特斯拉的超算系统也允许在更分散的模型中添加资源。 结语:特斯拉新技术或将吸引更多伙伴加入 综合来看,特斯拉超算调用了大量的资源,但是也很值得。相信特斯拉超算相关资料公布后,特斯拉的Dojo团队将吸引大批的技术爱好者加入。 另外,特斯拉在芯片和超算开发方面取得成就后,或将激励更多的车企加入到芯片和超算研发上来,大力发展自主创新能力,提升企业竞争力。
注:文章及图片转载自网络,如有侵权,请联系删除
|
 京公网安备 11010602105141号
京公网安备 11010602105141号
